C++基础笔记

这个是我在学习
C++语言中所记录的笔记,有可能会存在错误和遗漏,并且我有一点点C语言基础, 会大量的提及C语言与C++的不同,从而造成笔记晦涩; 另外C++的学习是一个长期且艰难的过程,因此本文进行了切分;
1 第一个程序
#include <iostream>
using namespace std;
int main(int argc, char *argv[])
{
cout << "Hello World" << endl;
return 0;
}编译指令

从生成的汇编指令来看,复杂不少
__cxx_global_var_init:
push {r11, lr}
mov r11, sp
sub sp, sp, #8
ldr r0, .LCPI0_0
.LPC0_0:
add r0, pc, r0
str r0, [sp, #4] @ 4-byte Spill
bl std::ios_base::Init::Init() [complete object constructor]
ldr r1, [sp, #4] @ 4-byte Reload
ldr r0, .LCPI0_1
.LPC0_1:
ldr r0, [pc, r0]
ldr r2, .LCPI0_2
.LPC0_2:
add r2, pc, r2
bl __cxa_atexit
mov sp, r11
pop {r11, lr}
bx lr
.LCPI0_0:
.long _ZStL8__ioinit-(.LPC0_0+8)
.LCPI0_1:
.Ltmp2:
.long _ZNSt8ios_base4InitD1Ev(GOT_PREL)-((.LPC0_1+8)-.Ltmp2)
.LCPI0_2:
.long __dso_handle-(.LPC0_2+8)
main:
push {r11, lr}
mov r11, sp
sub sp, sp, #16
mov r2, #0
str r2, [sp] @ 4-byte Spill
str r2, [r11, #-4]
str r0, [sp, #8]
str r1, [sp, #4]
ldr r0, .LCPI1_0
.LPC1_0:
ldr r0, [pc, r0]
ldr r1, .LCPI1_1
.LPC1_1:
add r1, pc, r1
bl std::basic_ostream<char, std::char_traits<char> >& std::operator<< <std::char_traits<char> >(std::basic_ostream<char, std::char_traits<char> >&, char const*)
ldr r1, .LCPI1_2
.LPC1_2:
ldr r1, [pc, r1]
bl std::basic_ostream<char, std::char_traits<char> >::operator<<(std::basic_ostream<char, std::char_traits<char> >& (*)(std::basic_ostream<char, std::char_traits<char> >&))
ldr r0, [sp] @ 4-byte Reload
mov sp, r11
pop {r11, lr}
bx lr
.LCPI1_0:
.Ltmp5:
.long _ZSt4cout(GOT_PREL)-((.LPC1_0+8)-.Ltmp5)
.LCPI1_1:
.long .L.str-(.LPC1_1+8)
.LCPI1_2:
.Ltmp6:
.long _ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_(GOT_PREL)-((.LPC1_2+8)-.Ltmp6)
_GLOBAL__sub_I_example.cpp:
push {r11, lr}
mov r11, sp
bl __cxx_global_var_init
pop {r11, lr}
bx lr
.L.str:
.asciz "Hello World"2 注释
2.1 C++注释
// 这个是一个单行注释
2.2 C注释
/*
这个里面是一个注释
*/在C/C++中两种注释都是可以使用的 并不是绝对的,只因为提出者是C或者C++
- 注释不影响程序的编译–>(预编译删除所有注释)
- 推荐使用doxygen–>(使用doxygen漂亮的注释)
3 标识符
3.1 变量
变量的存在意义:方便我们管理内存
变量创建的语法
存储类型 数据类型 变量名 = 变量初始化;- 自动,不使用标识符
- 寄存器(register)
- 静态static
- 外部extern
/* auto */ int a = 0; // C++不在添加自动变量标识符
static int a = 0; // 静态
register int a = 0; // 寄存器
extern int a = 0; // 外部
总结
| 存储类型 | 持续性 | 作用域 | 链接性 | 定义 |
|---|---|---|---|---|
| 自动变量 | 自动 | 函数内 | ❎ | 无标志符,定义在函数内 |
| 寄存器 | 自动 | 函数内 | ❎ | register |
| 静态 | 全局 | 函数内|文件内 | ❎ | static |
| 外部 | 全局 | 文件内 | ✅ | 无标志符,定义在文件内 |
3.2 常量
作用: 记录程序中不可以改变的数据
define宏常量(预编译期)const修饰变量(编译期)
3.3 关键字
| 关键字 | |||
|---|---|---|---|
| asm | else | new | this |
| auto | enum | operator | throw |
| bool | explicit | private | true |
| break | export | protected | try |
| case | extern | public | typedef |
| catch | false | register | typeid |
| char | float | reinterpret_cast | typename |
| class | for | return | union |
| const | friend | short | unsigned |
| const_cast | goto | signed | using |
| continue | if | sizeof | virtual |
| default | inline | static | void |
| delete | int | static_cast | volatile |
| do | long | struct | wchar_t |
| double | mutable | switch | while |
| dynamic_cast | namespace | template |
3.4 命名规则
- 标识符不可以是关键字
- 只能由字母、数字、下划线构成
- 第一个字母只能是字母或者是下划线
- 区分大小写
4 数据类型
指定类型,分配内存
4.1 整形
4.2 浮点型
- 单精度
float - 双精度
double
4.3 字符型
4.4 转义字符
4.5 字符串
- C风格
char 变量名[] = "字符串值";- C++风格
string 变量名 = "字符串值";4.6 布尔类型
bool A = true;
bool B = false;5 运算符
5.1 基本运算符
5.2 取模运算
就是取余数
5.3 自增自减运算
a1++;
a2--;5.4 赋值运算
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| = | |||
| += | |||
| -= | |||
| *= | |||
| /= | |||
| %= |
5.5 比较运算符
5.6 逻辑运算符
6 流程控制
6.1 顺序结构
6.1.1 if语句
// 情景1
if (条件) {
}
// 情景2
if (条件) {
} else {
}
// 情景3
if (条件1) {
} else if (条件2) {
} else {
}6.1.2 三目运算符
表达式1? 表达式2:表达式36.2 选择结构
switch(condition)
{
case 条件1:
break;
case 条件2:
break;
default:
break;
}6.3 循环结构
6.4 while循环
while(条件)
{
循环体;
}###do...while循环
do {
} while(条件)6.5 for循环
for (起始表达式; 条件表达式; 末尾循环体)
{
循环体;
}6.6 跳转语句
- break
- continue
6.6.1 goto
绝对跳转语句
7 函数定义
- 返回值类型
- 函数名
- 参数列表
- 函数体语句
return表达式
返回值类型 函数名字(参数列表)
{
函数体语句;
return 表达式;
}7.1 值传递
类似数值拷贝
7.2 函数的常见样式
- 无参无返
- 有参无返
- 无参有反
- 有参有返
7.3 声明
作用: 告诉编译器函数名以及调用方式,函数实体可以单独实现;
7.4 多文件
8 复合数据结构
8.1 数组
8.2 指针
8.2.1 指针的定义和使用
8.2.2 指针所占用空间
8.2.3 空指针
含义: 指针指向内存空间为0的指针; 用途: 初始化指针变量 注意: 空指针的地址是不可以访问的
8.2.4 野指针
指针指向非法的内存空间
8.2.5 const与指针
- const修饰指针
- const修饰常量
- const既修饰指针又修饰常量
const int *p = &a;
int const *p = &a;
const int *const p = &a;8.2.6 指针与数组
8.2.7 指针与函数
8.3 结构体
8.3.1 结构体数组
8.3.2 结构体指针
8.3.3 结构体嵌套
8.4 枚举
8.5 联合
8.6 位域
9 C++内存分区
c++程序在运行时,将内存分为4个区域
- 代码区: 存放程序的二进制代码,由操作系统管理
- 全局区: 存放全局变量、静态变量和常量
- 栈区: 编译器自动分配
- 堆区: 程序负责分配和释放
10 new/delete操作符
- new操作符在堆区开辟内存
- delete释放内存对象
11 引用
作用: 给变量起别名 语法: 数据类型 &别名 = 原名;
11.1 引用做参数
#include <iostream>
void swap(int &a, int &b)
{
int t; t = a;a = b;b = t;
}
int main(int argc, char *argv[])
{
int a = 10;int b = 12;
std::cout << "交换前" << a << '\t' << b << std::endl;
swap(a, b);
std::cout << "交换后" << a << '\t' << b << std::endl;
return 0;
}执行结果
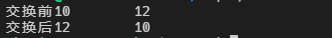
11.2 引用做返回值
11.3 引用的本质
引用的本质是C++内部实现的一个指针常量
11.4 常量引用
const int &ref = 10;12 函数提高
12.1 函数默认值
- 某个位置有默认值,那么后面的参数也必须由默认值
- 如果声明了默认值,那么实现不可以有默认值(默认参数会产生冲突)
void test_default_param(int a = 0, int b = 0, int c = 0)
{
std::cout << a + b + c << std::endl;
}12.2 函数的占位参数
占位参数还可以有默认值
void test(int a, int = 10) {
std::cout << a << std::endl;
}12.3 函数重载
作用:函数名相同,提高复用性
重载的条件:
相同作用域
函数名相同
参数不同(类型, 个数,顺序)
注意事项:
- 引用作为重载条件
- 函数重载碰到默认参数
13 命名空间
namespace/using关键字
命名空间(Namespace)是一种用于避免命名冲突的机制,它能够将众多的全局变量、函数和类组织在一起,形成一个独立的命名空间,从而避免不同代码块中的同名标识符发生冲突。下面是C++命名空间的详解:
- 命名空间的定义
命名空间可以通过使用关键字"namespace"来定义,其语法格式如下:
namespace namespace_name {
// namespace body
}其中,namespace_name表示命名空间的名称,花括号内的部分为命名空间的主体,可以包含变量、函数和类等。
- 命名空间的使用
命名空间可以通过两种方式进行使用:
(1)使用命名空间前缀
可以通过加上命名空间前缀的方式访问该命名空间中的元素。例如:
namespace ns {
void func() { ... }
}
int main() {
ns::func(); // 调用ns命名空间中的函数func()
}(2)using声明
也可以通过using声明的方式引入指定命名空间中的元素,以便于直接使用。例如:
namespace ns {
void func() { ... }
}
using ns::func; // 引入ns命名空间中的函数func()
int main() {
func(); // 直接调用func()
}需要注意的是,using声明污染了当前命名空间的作用域,可能会导致命名冲突。
- 命名空间的嵌套
C++中,命名空间可以进行嵌套,从而形成多级命名空间。例如:
namespace ns1 {
namespace ns2 {
void func() { ... }
}
}
int main() {
ns1::ns2::func(); // 调用ns1::ns2命名空间中的函数func()
}- 匿名命名空间
C++还支持匿名命名空间,它定义在全局命名空间内,但是该命名空间的名称为空。在匿名命名空间内定义的变量、函数和类等被视为静态的,只能在当前文件内使用。例如:
namespace {
int x; // 定义一个静态变量x
}
int main() {
x = 10; // 错误:无法访问匿名命名空间内的变量x
return 0;
}以上就是C++命名空间的详细介绍,通过合理使用命名空间可以避免不同代码块中的同名标识符发生冲突,提高程序的可读性和可维护性。
using关键字用法分析
- using声明
using声明可以用于将指定的命名空间或名称引入当前作用域,以便于直接使用。例如:
#include <iostream>
// 引入std命名空间中的cout和endl
using std::cout;
using std::endl;
int main() {
cout << "Hello, world!" << endl;
return 0;
}在上面的例子中,使用了using声明将std命名空间中的cout和endl引入到了main函数的作用域中,从而可以直接使用它们输出文本信息。
需要注意的是,using声明可能会导致命名冲突,因此应当谨慎使用。
- using指令
using指令可以用于将所指向的命名空间中的所有名称都引入当前作用域,以便于直接使用。例如:
#include <iostream>
// 引入std命名空间中的所有名称
using namespace std;
int main() {
cout << "Hello, world!" << endl;
return 0;
}在上面的例子中,使用了using指令将std命名空间中的所有名称都引入到了main函数的作用域中,从而可以直接使用其中的cout和endl等标准库函数。
需要注意的是,使用using指令会将整个命名空间的所有名称都引入到当前作用域中,可能会导致命名冲突和名称重定义等问题。因此,建议在较小的作用域内使用using声明,而尽量避免使用using指令。
- using别名
using别名可以用于为一个类型或值定义一个新的名称,以便于更加方便地使用它们。例如:
#include <iostream>
// 定义int型别名myInt
using myInt = int;
int main() {
myInt x = 10;
std::cout << x << std::endl;
return 0;
}在上面的例子中,使用了using别名将int型定义为了myInt的别名,从而可以在程序中使用myInt来代替int类型。
需要注意的是,使用using别名会增加代码的可读性,但也可能导致代码可读性下降。因此,在定义别名时应当保持适度,避免过多使用。
14 异常处理
C++ 异常是一种程序运行时可能发生的错误,它们通常是程序中的逻辑或者数据错误,例如除以零、访问空指针、数组越界等。当这些错误发生时,程序会抛出异常,并且执行相应的异常处理代码。
C++ 中的异常处理机制有三个关键字:try、catch 和 throw。其中,try 块中包含可能会抛出异常的代码,catch 块用于捕获并处理异常,throw 关键字用于在代码中显式地抛出异常。
下面是一个简单的 C++ 异常处理示例:
#include <iostream>
using namespace std;
int main() {
try {
int x = 10, y = 0;
if (y == 0) {
throw "Divide by zero exception";
}
int z = x / y;
cout << "Result: " << z << endl;
} catch (const char* msg) {
cerr << "Error: " << msg << endl;
}
return 0;
}在上面的代码中,我们使用 try 块来包含可能会抛出异常的代码,如果 y 的值为 0,则使用 throw 关键字抛出一个字符串类型的异常信息;catch 块用于捕获并处理异常,这里我们捕获了一个 const char* 类型的异常信息,并将其打印到标准错误流中。
除了字符串类型的异常信息,C++ 还支持其他类型的异常信息,例如整型、浮点型和自定义类型等。在 catch 块中,我们可以根据异常类型来选择不同的处理方式。
需要注意的是,C++ 异常处理机制虽然可以帮助我们处理程序运行时的错误,但是过度使用异常处理机制也会对程序的性能和可维护性产生影响。因此,在使用异常处理机制时,我们应该尽量避免频繁抛出和捕获异常,并尽可能地将异常处理代码集中到一个地方,以提高程序的可读性和可维护性。
C++异常处理的底层原理主要涉及3个方面:抛出异常、捕获异常和栈展开。
当程序执行过程中发生错误时,会通过throw语句抛出一个异常。throw语句将异常对象传递到栈上,然后继续往上传递直到被捕获或者到达程序的最外层。
当异常被抛出后,程序会在调用栈上查找符合类型匹配的catch子句。如果找到匹配的catch子句,则程序会跳转到该catch子句的代码块中继续执行,并且执行完成后不会再返回到抛出异常的位置。
如果没有找到符合类型匹配的catch子句,则程序会沿着调用栈继续查找,直到到达程序的最外层。如果在整个调用栈上都没有找到合适的catch子句,则程序会终止并输出未处理的异常信息。
栈展开是指当异常被抛出时,程序会回溯调用栈,并且在每个函数中查找是否存在try-catch块。如果存在,则程序会在该try-catch块中查找是否有匹配的catch子句,并且执行相应的操作。如果不存在,则程序会继续向上回溯调用栈,直到找到匹配的catch子句或者到达程序的最外层。
总之,C++异常处理的底层原理是通过在调用栈上传递和捕获异常对象,并且执行栈展开来实现的。这种机制使得程序可以在发生错误时,及时地停止当前操作,并且提供一种机制来处理和恢复执行过程中出现的错误。
