Python学习笔记

python学习笔记
1 开发环境安装
推荐Mambaforge,与anaconda相同功能,但是速度更加快;
mamba是包管理器的重新实现,由C++重新实现,主页地址:miniforge,
1.1 安装软件
$ curl -L -O "https://github.com/conda-forge/miniforge/releases/latest/download/Mambaforge-$(uname)-$(uname -m).sh"
$ bash Mambaforge-$(uname)-$(uname -m).sh1.2 配置环境
CONDA_EXE=mamba- 配置虚拟环境
conda env list #查看虚拟环境
mamba create -n env_name -y #创建
conda activate env_name #激活
conda deactivate #退出- 配置包下载镜像
mamba config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
mamba config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
mamba config --set show_channel_urls yes1.3 jupyter notebook/lab安装
1.3.1 1. 安装
$ mamaba install jupyter1.3.2 2. 配置
- ssh远程使用jupyter notebook
# 远程服务器开启
jupyter notebook --no-browser --port=8889
# ssh forward端口
ssh -N -f -L localhost:8888:localhost:8889 username@serverIP- 利用jupyter notebook自带的远程访问功能
# 1. 生成默认配置文件
jupyter notebook --generate-config
# 2.1 自动生成访问密码(token)
jupyter notebook password
Enter password:
Verify password:
[NotebookPasswordApp] Wrote hashed password to ${HOME}/.jupyter/jupyter_notebook_config.json
# 2.2 手动生成访问密码(token)
In [1]: from notebook.auth import passwd
# 2.2.1 官方教程默认情况下生成sha1,但实际情况生成了argon2
In [2]: passwd()
Enter password:
Verify password:
Out[2]: 'argon2:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
# 2.2.2 输入sha1的生成算法,即可得到
In [3]: passwd(algorithm='sha1')
Enter password:
Verify password:
Out[3]: 'sha1:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
# 3. 修改./jupyter/jupyter_notebook_config.py
c.NotebookApp.ip='*'
c.NotebookApp.password = u'sha:ce...刚才复制的那个密文'
c.NotebookApp.open_browser = False
c.NotebookApp.port =8888 #可自行指定一个端口, 访问时使用该端口
# 如果是自动的形式此时就可以直接访问
# 4. 配置相关
c.ServerApp.allow_remote_access = True
c.LabApp.open_browser = False1.3.3 安装扩展
- jupyter_contrib_nbextensions,
pip install jupyter_contrib_nbextensions
jupyter contrib nbextension install --user- Jupyter Nbextensions Configurator
pip install jupyter_nbextensions_configurator
jupyter nbextensions_configurator enable --user1.4 安装C++ Kernel
conda install xeus-cling -c conda-forge安装结束,进行测试
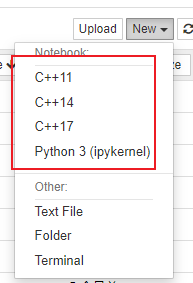
可以看到新的几个kernel
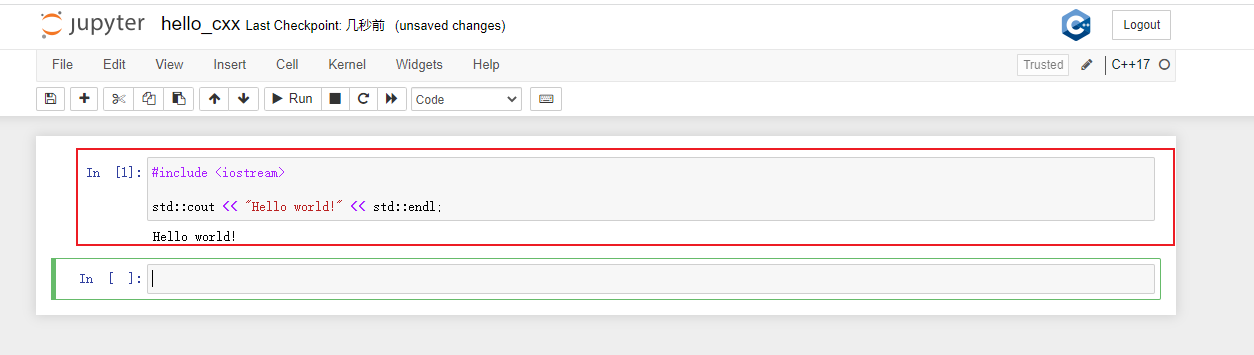
2 python入门
2.1 第一个程序
#!/bin/python3
from rich import print
if __name__ == '__main__':
print('Hello World')2.2 打印一个彩蛋
import this
# 打印结果
# The Zen of Python, by Tim Peters
# Beautiful is better than ugly.
# Explicit is better than implicit.
# Simple is better than complex.
# Complex is better than complicated.
# Flat is better than nested.
# Sparse is better than dense.
# Readability counts.
# Special cases aren't special enough to break the rules.
# Although practicality beats purity.
# Errors should never pass silently.
# Unless explicitly silenced.
# In the face of ambiguity, refuse the temptation to guess.
# There should be one-- and preferably only one --obvious way to do it.
# Although that way may not be obvious at first unless you're Dutch.
# Now is better than never.
# Although never is often better than *right* now.
# If the implementation is hard to explain, it's a bad idea.
# If the implementation is easy to explain, it may be a good idea.
# Namespaces are one honking great idea -- let's do more of those!添加一个打印函数
# 使用rich打印
from rich import print
print("Rich Print")Rich中的打印更加漂亮
2.3 字符串格式化
- 使用 格式化字符串字面值 ,要在字符串开头的引号/三引号前添加 f 或 F 。在这种字符串中,可以在 { 和 } 字符之间输入引用的变量,或字面值的 Python 表达式。
>>> year = 2016
>>> event = 'Referendum'
>>> f'Results of the {year} {event}'
'Results of the 2016 Referendum'- 字符串的 str.format() 方法需要更多手动操作。该方法也用 { 和 } 标记替换变量的位置,虽然这种方法支持详细的格式化指令,但需要提供格式化信息。
>>> yes_votes = 42_572_654
>>> no_votes = 43_132_495
>>> percentage = yes_votes / (yes_votes + no_votes)
>>> '{:-9} YES votes {:2.2%}'.format(yes_votes, percentage)
' 42572654 YES votes 49.67%'- 旧式字符串格式化方法 不在使用了,还是新的看着舒服
2.4 main函数
python中并不会存在着main函数,当前只是模拟了一个入口函数
if __name__ == '__main__':
main()3 数据类型
3.1 Numbers(数字)
- int
- long
- float
- double
intA = int(12)
print(type(intA))<class 'int'>
longB = 0xDAEABEEF
print(type(longB))<class 'int'>
floatC = 1.2
print(type(floatC))<class 'float'>
doubleD = 1.2
print(type(doubleD))<class 'float'>
3.2 布尔类型
- True
- False
boolA = True
boolB = False
print(boolA, type(boolA))
print(boolB, type(boolB))True <class 'bool'>
False <class 'bool'>
3.3 String(字符串)
- 使用"“定义字符串
- r在字符串表示禁止转义
- 使用”““作用长字符串
# 普通定义字符串
strA = "Hello"
print(strA, type(strA))
# r禁止转义
strB = r"Hello\nWorld"
print(strB, type(strB))
# 长字符串
strC = """
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
"""
print(strC, str(strC))Hello <class 'str'>
Hello\nWorld <class 'str'>
The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those! The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!
3.4 List(列表)
listC = ["12", 3, 4]
print(listC)3.5 Tuple(元组)
tupleD = ('physics', 'chemistry', 1997, 2000)
print(tupleD)3.6 Dictionary(字典)
DictE = {'a': 1, 'b': 2, 'b': '3'}
print(DictE)3.7 set(集合)
SetF = set([1, 2, 3, 3])
print(DictE)4 运算符
5 控制结构
5.1 单执行语句
if 判断条件:
执行语句
else:
执行语句5.2 多条件语句
if 判断条件1:
执行语句1……
elif 判断条件2:
执行语句2……
elif 判断条件3:
执行语句3……
else:
执行语句4……5.3 match语句
match语句类似于c的switch语句,
match status:
case 400:
return "Bad request"
case 404:
return "Not found"
case 418:
return "I'm a teapot"
case _:
return "Something's wrong with the internet"5.4 while循环
c = 0
while (c < 10):
print(c)
c += 1
print("while Loop finish")5.5 for语句
python中的语句与C不同,python不进行数值的计算,而是 迭代列表或字符串等任意序列,元素的迭代顺序与在序列中出现的顺序一致
# 定义一个列表
words = ["linux", "macos", "windows"]
# 遍历列表
for word in words:
print(word, len(word))源码文件:
执行结果:
5.6 range函数
内置函数
range()常用于遍历数字序列,该函数可以生成算术级数
range的语法
# start: 开始
# stop: 结束
# step: 步长
range(start, stop, step)那么是如何排列的
- 只有一个参数下只会只存在stop
for i in range(10):
print(i)源码文件:
执行结果:
- 两个参数下存在start和stop
for i in range(1, 10):
print(i)源码文件:
执行结果:
- 三个参数全部填写
for i in range(1, 10, 2):
print(i)源码文件:
执行结果:
如果直接输出range会发生什么
range()返回对象的操作和列表很像,但其实这两种对象不是一回事. 迭代时,该对象基于所需序列返回连续项,并没有生成真正的列表,从而节省了空间。 这种对象称为可迭代对象 iterable,函数或程序结构可通过该对象获取连续项,直到所有元素全部迭代完毕
将range对象强转为其他类型的数据结构
字典是无法进行转换的
l = list(range(10))
t = tuple(range(10))
s = set(range(10))5.7 跳出语句
break语句和C中的类似,用于跳出最近的for或while循环。
for n in range(2, 10):
for x in range(2, n):
if n % x == 0:
print(n, 'equals', x, '*', n//x)
break
else:
print(n, 'is a prime number')但是与C不相同的是,else可以用于for语句,未执行break时执行
5.8 pass语句
pass语句不执行任何操作
6 函数
- 定义函数使用关键字
def, 后跟函数名与括号内的形参列表.函数语句从下一行开始,并且必须缩进. - 函数内的第一条语句是字符串时,该字符串就是文档字符串,也称为
docstring,详见文档字符串。利用文档字符串可以自动生成在线文档或打印版文档,还可以让开发者在浏览代码时直接查阅文档;Python开发者最好养成在代码中加入文档字符串的好习惯. - 函数在执行时使用函数局部变量符号表,所有函数变量赋值都存在局部符号表中;引用变量时,首先,在局部符号表里查找变量,然后,是外层函数局部符号表,再是全局符号表,最后是内置名称符号表。因此,尽管可以引用全局变量和外层函数的变量,但最好不要在函数内直接赋值(除非是
global语句定义的全局变量,nonlocal语句定义的外层函数变量)
6.1 函数参数
从函数定义的角度来看,参数可以分为两种:
必选参数:调用函数时必须要指定的参数,在定义时没有等号可选参数:也叫默认参数,调用函数时可以指定也可以不指定,不指定就默认的参数值来。
从函数调用的角度来看,参数可以分为两种:
关键字参数:调用时,使用 key=value 形式传参的,这样传递参数就可以不按定义顺序来。位置参数:调用时,不使用关键字参数的 key-value 形式传参,这样传参要注意按照函数定义时参数的顺序来。
def func(a,b,c=0, d=1):
pass- a,b称为必选参数
- c,d称为可选参数
可变参数,类似C语言的...参数
加了星号*的变量名会存放所有未命名的变量参数
# 定义函数
def hello(head, *args):
for arg in args:
print(f"{head}:{arg}")
return True
# 调用函数
hello("ERROR", 1, 2, 3)
$ ERROR:1
$ ERROR:2
$ ERROR:36.2 匿名函数
lambda关键字用于创建小巧的匿名函数;
lambda a, b: a+b 函数返回两个参数的和。Lambda 函数可用于任何需要函数对象的地方。在语法上,匿名函数只能是单个表达式。在语义上,它只是常规函数定义的语法糖。与嵌套函数定义一样,lambda 函数可以引用包含作用域中的变量:
>>> pairs = [(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four')]
>>> pairs.sort(key=lambda pair: pair[1])
>>> pairs
[(4, 'four'), (1, 'one'), (3, 'three'), (2, 'two')]6.3 文档字符串
对函数进行注释
>>> def func():
... """
... Do Nothing
... 仅仅作为演示
... """
... pass
...
>>> print(func.__doc__)
Do Nothing6.4 函数注解
函数注解是可选的用户自定义函数类型的元数据完整信息(详见PEP3107和PEP484)
标注 以字典的形式存放在函数的 annotations 属性中而对函数的其他部分没有影响
- 形参标注的定义方式是在形参名后加冒号,后面跟一个会被求值为标注的值的表达式。
- 返回值标注的定义方式是加组合符号 ->,后面跟一个表达式,这样的校注位于形参列表和表示 def 语句结束的冒号
>>> def f(ham: str, eggs: str = 'eggs') -> str:
... return ham + ' and ' + eggs
>>> f('spam')
'spam and eggs'
>>> f.__annotations__
{'ham': <class 'str'>, 'eggs': <class 'str'>, 'return': <class 'str'>}7 模块
8 异常处理
即使语句或表达式使用了正确的语法,执行时仍可能触发错误
while True:
try:
x = int(input("Please enter a number: "))
break
except ValueError:
print("Oops! That was no valid number. Try again...")执行结果:
D:\python\异常处理\.venv\Scripts\python.exe D:\python\异常处理\main.py
Please enter a number: a
Oops! That was no valid number. Try again...
Please enter a number: 12
Process finished with exit code 09 文件操作
9.1 文件打开模式
打开文件获取文件描述符,打开文件时需要指定对文件的读写模式,和写追加模式。常见的文件模式如下:
| 模式 | 描述 |
|---|---|
| ‘r’ | 以只读方式打开文件(默认),不存在报错 FileNotFoundError |
| ‘w’ | 以写方式打开文件,如果文件存在,首先清空原内容,如果不存在先创建文件 |
| ‘x’ | 以写方式打开文件,如果文件存在,则报错 FileExistsError |
| ‘a’ | 以写方式打开文件,并追加内容到文件结尾,如果文件不能存在则先创建文件 |
| ‘+’ | 可同时读写 |
9.2 打开文件(open函数)
open(file, mode='r', buffering=-1, encoding=None, errors=None,
newline=None, closefd=True, opener=None)
Open file and return a stream. Raise IOError upon failure.测试代码
# shell echo "Hello World" >> test
Python 3.11.6 (main, Nov 14 2023, 09:36:21) [GCC 13.2.1 20230801] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> f = open('test.txt', 'r', encoding='utf-8')
>>> print(f.read())
Hello World
>>> f.close()但是这个写法不太好,如果文件打开出现异常,程序会出现崩溃(加上异常处理)
f = None
try:
f = open('test.txt', 'r', encoding='utf-8')
print(f.read())
except FileNotFoundError:
print('无法打开指定的文件!')
except LookupError:
print('指定了未知的编码!')
except UnicodeDecodeError:
print('读取文件时解码错误!')
finally:
if f:
f.close()加上with关键字,在正常的情况下我们不需要进行手动关闭
def main():
try:
with open('致橡树.txt', 'r', encoding='utf-8') as f:
print(f.read())
except FileNotFoundError:
print('无法打开指定的文件!')
except LookupError:
print('指定了未知的编码!')
except UnicodeDecodeError:
print('读取文件时解码错误!')
if __name__ == '__main__':
main()9.3 文件描述符的属性
在 Python 中,文件描述符就是一个文件对象,它具有如下属性:
| 属性 | 描述 |
|---|---|
| file.closed | 返回布尔值,True 已被关闭。 |
| file.mode | 返回被打开文件的访问模式。 |
| file.name | 返回文件的名称。 |
9.4 读取文件
>>> f = open('test.txt', 'r', encoding='utf-8')
>>> f.read()
'Hello World\n'
>>> f.readline()
''
>>> f.readlines()
[]
>>> type(f.readline())
<class 'str'>
>>> type(f.readlines())
<class 'list'>
>>> type(f.read())
<class 'str'>9.5 写入文件
10 正则表达式
11 进程线程
12 面向对象
面向对象编程(Object Oriented Programming,OOP)是一种程序设计思想。它把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数,相同属:性和操作方法的对象被抽象为类。类(Class)就类似上面所说的模具,而对象(Object)就是使用模具生产出的零件,对象就是类的实例(Instance)
继承和多态、封装是面向对象编程的三个基本特征
print(isinstance(object, type))
print(isinstance(type, object))
print(isinstance(type, type))
print(isinstance(object, object))
>>>
True
True
True
True12.1 类和对象
在Python中可以使用
class关键字定义类,然后在类中通过之前学习过的函数来> 定义方法,这样就可以将对象的动态特征描述出来,代码如下所示。
# 1.1 定义类
class clsTest:
clsNum = 0
def clsFunc(self):
print("执行方法")
# 1.2 实例化对象
t = clsTest()
t.clsFunc()说明: 写在类中的函数,我们通常称之为(对象的)方法,这些方法就是对象可以接收的消息。
12.2 抽象/封装/继承/多态
12.3 属性
12.4 方法
12.5 运算符重载
12.6 类对象
12.7 继承和多态
13 标准库
14 虚拟环境
- 创建虚拟环境
virtualenv envName- 激活环境
cd envName
source ./bin/activate- 销毁环境
deactivate15 GUI基础(pyQt)
15.1 打印版本号
from PyQt6.QtCore import QT_VERSION_STR
from PyQt6.QtCore import PYQT_VERSION_STR
print(f'QT_VERSION_STR ==> {QT_VERSION_STR}')
print(f'PYQT_VERSION_STR ==> {PYQT_VERSION_STR}')运行结果
QT_VERSION_STR ==> 6.8.1
PYQT_VERSION_STR ==> 6.8.015.2 运行widgets
#!/bin/env python3
import sys
from PyQt6.QtWidgets import QWidget, QApplication
app = QApplication(sys.argv)
widget = QWidget()
widget.resize(640, 480)
widget.setWindowTitle("Hello, PyQt6!")
widget.show()
sys.exit(app.exec())
15.3 PyQt6 日期和时间
#!/usr/bin/python
from PyQt6.QtCore import QDate, QTime, QDateTime, Qt
now = QDate.currentDate()
print(now.toString(Qt.DateFormat.ISODate))
print(now.toString(Qt.DateFormat.RFC2822Date))
datetime = QDateTime.currentDateTime()
print(datetime.toString())
time = QTime.currentTime()
print(time.toString(Qt.DateFormat.ISODate))打印结果
2025-01-01
01 Jan 2025
Wed Jan 1 20:01:17 2025
20:01:1715.4 pyQt6状态栏
#!/usr/bin/python
"""
PyQt6 tutorial
This program creates a statusbar.
"""
import sys
from PyQt6.QtWidgets import QMainWindow, QApplication
class Example(QMainWindow):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
self.statusBar().showMessage('Ready')
self.setGeometry(300, 300, 350, 250)
self.setWindowTitle('Statusbar')
self.show()
def main():
app = QApplication(sys.argv)
ex = Example()
sys.exit(app.exec())
if __name__ == '__main__':
main()15.5 pyQt6菜单
#!/usr/bin/python
"""
PyQt6 tutorial
This program creates a menubar. The
menubar has one menu with an exit action.
"""
import sys
from PyQt6.QtWidgets import QMainWindow, QApplication
from PyQt6.QtGui import QIcon, QAction
class Example(QMainWindow):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
exitAct = QAction(QIcon('exit.png'), '&Exit', self)
exitAct.setShortcut('Ctrl+Q')
exitAct.setStatusTip('Exit application')
exitAct.triggered.connect(QApplication.instance().quit)
self.statusBar()
menubar = self.menuBar()
fileMenu = menubar.addMenu('&File')
fileMenu.addAction(exitAct)
self.setGeometry(300, 300, 350, 250)
self.setWindowTitle('Simple menu')
self.show()
def main():
app = QApplication(sys.argv)
ex = Example()
sys.exit(app.exec())
if __name__ == '__main__':
main()15.6 pyQt6布局管理
TODO
15.7 PyQt6 事件和信号
TODO
15.8 PyQt6 的对话框
TODO
16 python打包
